

“Who has access?” is a trick question
And why most access reviews fail to answer it
Every security team has been asked this question. An auditor walks in, a compliance framework demands it, an incident responder needs it urgently: who has access to this resource?
It sounds like simple question any team should have an immediate answer to.
However, this question is underspecified in ways that most organizations never bother to articulate, and the result is that access reviews produce answers that range from incomplete to meaningless. Not because the teams doing them are necessarily incompetent, but because the industry lacks a shared understanding for what “access” actually means in practice.
The problem with “access”
Suppose you’re asked: who can edit DNS records in Cloud DNS on Google Cloud Platform?
Your first instinct might be to check who has the dns.changes.create permission on the DNS zone. You look at any predefined and custom IAM roles containing that permission, IAM bindings for that resource, find the employees with matching roles, and hand over a list.
Except that list is incomplete in ways you (or your auditor) haven’t scoped.
Maybe a user doesn’t have the permission directly, but they’re in a group that does. Maybe the binding isn’t on the zone itself, but on the project that contains it, or the folder above that project, or the organization above that folder. Maybe the user has no binding anywhere, but they can impersonate a service account that does. Maybe they can impersonate a service account that can impersonate another service account that has access through a group membership inherited from a folder three levels up. Maybe the user has no current access at all, but they possess the power to grant it to themselves at any time: a permission that only wakes up when they decide to edit an IAM policy or role somewhere else.
All of these are real and all of them answer “who has access” differently. However, most access reviews stop looking at the first or second layer.
The root issue is that we’re conflating fundamentally different things under a single word. To have a useful conversation about access, I believe it’s necessary to distinguish between three broad categories: effective access, assumable access, and escalatable access.
The examples throughout this article use Google Cloud Platform because that’s where I work the most daily, but nothing here is GCP-specific. AWS has an arguably more complex IAM system, with largely the same patterns involving IAM roles, SCPs, resource policies, and cross-account role assumption. Azure has management group inheritance, managed identities, and service principal impersonation. Hence, the underlying problem is structural: any system with hierarchical resource organization, group-based policy resolution, and delegated identity mechanisms will produce the same complexity.
Effective access
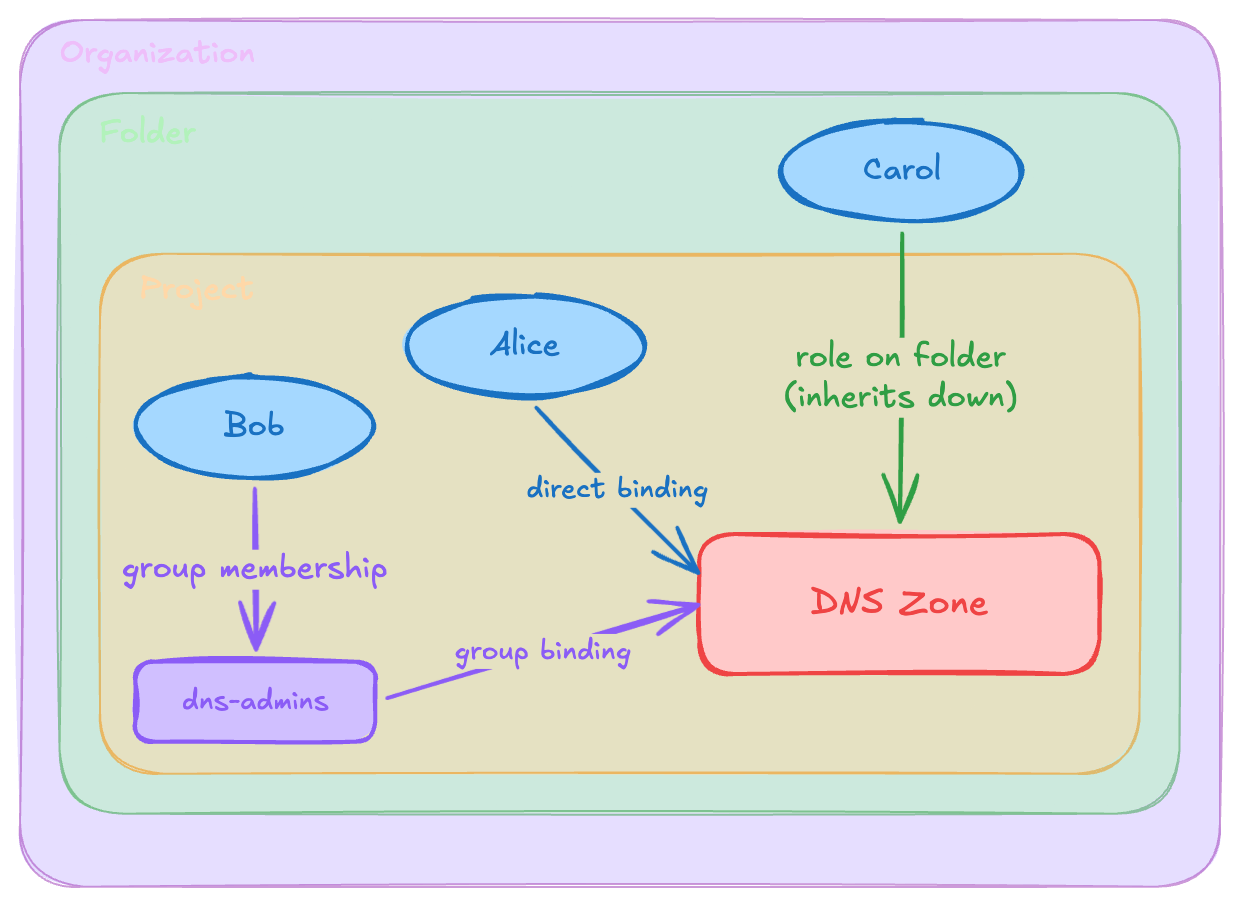
Effective access is the set of permissions a principal can exercise right now, without performing any intermediate action. The principal navigates to the resource, performs the operation, and it works. No impersonation, no credential exchange, no role modification needed.
This is what most people picture when they hear “access,” but even this category is more complex than it first appears. The principal might hold the permission through any of several mechanisms:
The simplest is a direct binding: the user is bound to a role containing the permission on the resource itself. Then there’s group-mediated access: the user is a member of a group (or a complex nested chain of groups) that holds the binding. On top of this, there’s hierarchy inheritance: the binding exists on an ancestor resource, such as a project, folder, or organization, and propagates down.
These mechanisms are orthogonal and composable: a user might be a member of a group that is a member of another group that has a role binding on a folder, and that binding propagates to a project, which contains the resource. The result is an access path of length four or five, but the access is still effective, meaning the user can exercise the permission immediately, right now, without doing anything first.
The length of the access path matters, but not for whether the access exists. It matters for auditability. A direct binding on a resource is visible, easy to review and more likely to be intentional, while a nested group membership inherited through three layers of resource hierarchy is harder to discover, and more likely to be accidental or ungoverned. Access path length can be a useful proxy to determine how likely the access is unintentional.
Assumable access
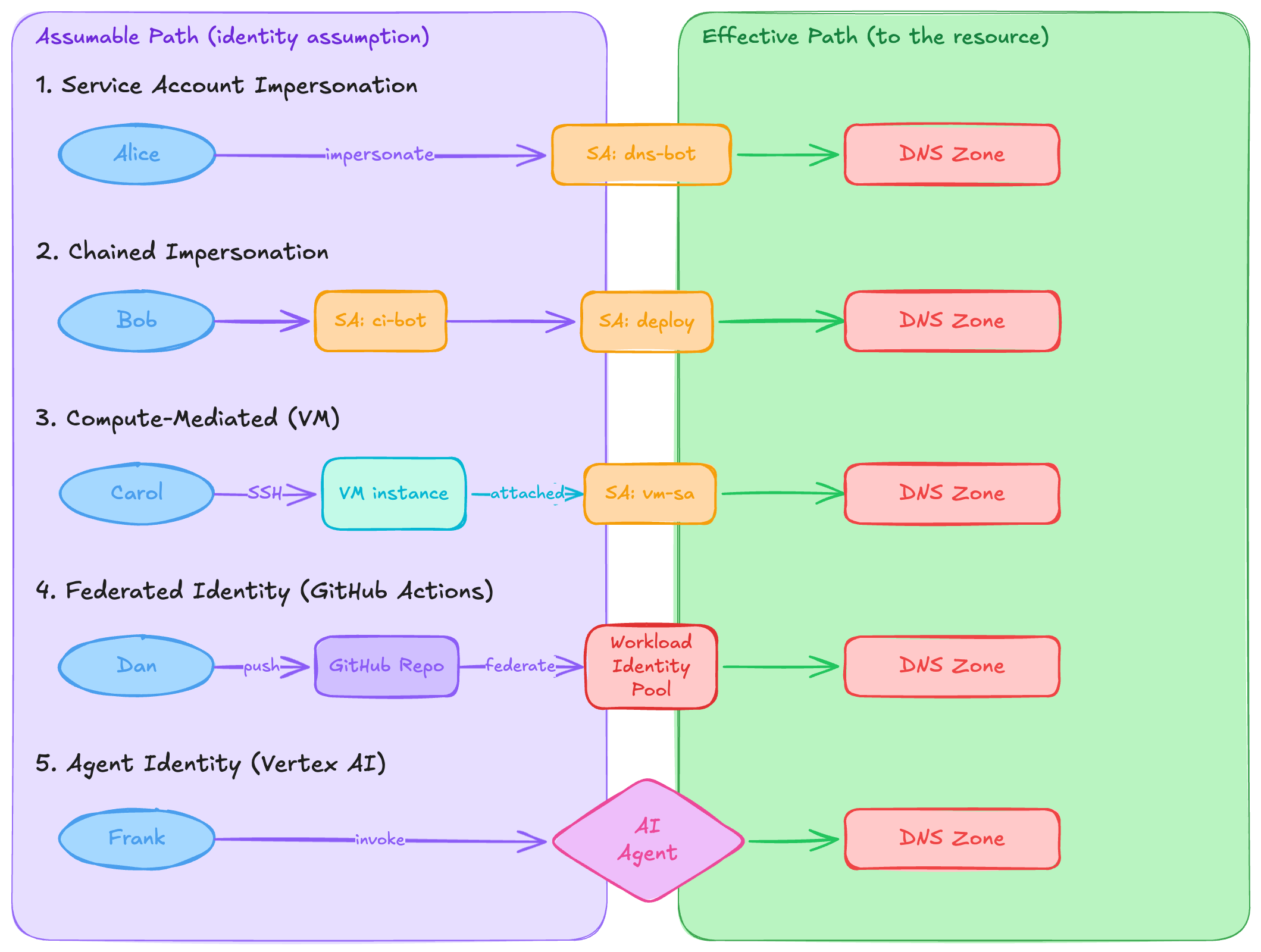
Assumable access is when a principal does not have effective access to a resource, but can obtain it by assuming a different identity. The defining operation here is identity impersonation: the principal temporarily becomes another principal and inherits that principal’s effective access in whole or in part.
The most obvious example in GCP is service account impersonation. A user with the iam.serviceAccounts.getAccessToken permission on a service account can mint tokens as that service account. If the service account has effective access to the resource, the user can reach it through impersonation. And just like effective access, the service account’s path to the resource itself might be mediated through groups, inheritance, or both.
This creates two independent path dimensions. The assumable path is the chain of identity assumptions: how does the user reach the target identity? The effective path is the chain from that identity to the resource. The composition of both results in the total access path.
Service account impersonation can also chain. A user impersonates service account A, which can impersonate service account B, which has the role binding. Each hop adds a layer of indirection and, more often than not, a layer of unintentionality.
But impersonation through the IAM API isn’t the only way to assume an identity. Consider a user who can SSH into a VM, or deploy code to a Cloud Run service, or trigger a Cloud Build pipeline. Each of these workloads runs with an attached service account. If the user can execute arbitrary code in a workload’s context, they effectively have access to its credentials. This is identity assumption through compute access rather than through the IAM impersonation API, but the end result is the same: the user acts as the service account.
These paths are harder to enumerate because they cross the boundary between IAM analysis and infrastructure or application analysis. IAM tooling can tell you who can impersonate a service account. Understanding that a user can push code to a Cloud Run service which runs as that service account requires understanding the deployment pipeline, repository permissions, and CI/CD configuration. The access path exists, but because it lives in a different system it’s easy to overlook it.
Where federated identities fit
Identity federation adds another dimension to assumable access. In workload identity federation, an external identity, such as a GitHub Actions runner, an AWS role, or a CI/CD pipeline in another platform, can exchange its native credentials for short-lived GCP credentials. The federation configuration defines which external identities map to which GCP principals.
This means the question of “who has access” can extend outside your cloud boundary entirely. If a GitHub Actions workflow for a specific repository has federated access to a GCP service account, then anyone who can create or modify workflows in that repository effectively has assumable access to whatever that service account can reach. The user’s credential never touches GCP directly: they push a commit to a repository, a workflow runs, it federates into a GCP identity, and that principal has effective access to your resources.
Federated identity is particularly challenging for access reviews because the trust boundary is defined in configuration of the workload identity pool and in an external system’s permission model. You won’t find these paths by examining role bindings just in the resource’s platform alone. You need to trace the federation configuration, understand the external identity provider’s authorization model, and map backward from “who can assume this external identity” all the way to “which principals are able to grant or influence access along that path.”
The AI agent identity problem
This is about to get even more complicated. Cloud providers are introducing first-class identity types for AI agents, and these create entirely new assumable access paths.
Google Cloud’s Vertex AI Agent Engine now supports agent identity as an IAM principal type. Agents get their own principal identifiers in the format principal://TRUST_DOMAIN/NAMESPACE/AGENT_NAME, and you can bind IAM roles to these identities just like you would for users or service accounts. From an access review perspective, this means agents are principals that can hold effective access to resources.
Where they differ from traditional service accounts is in their constraints. Agent identities cannot be directly impersonated by another principal through the IAM API. There are also no downloadable keys to create, rotate, or leak. The credentials are cryptographically bound to the agent's runtime environment on Vertex AI through certificate-bound tokens and mTLS, which means stolen credentials are not replayable outside that context. In practice, they are more restricted service accounts: scoped to a specific workload, tied to its lifecycle, and stripped of the portability that makes service accounts both useful and dangerous. This matters for access analysis because the assumable access path to an agent's permissions doesn't run through impersonation or credential theft. It only runs through the ability to invoke the agent itself, which is a fundamentally different trust boundary.
The assumable access question then becomes: who can invoke the agent? If a user can send requests to an agent, and that agent has IAM permissions to perform actions on resources, the user has indirect access to those resources through the agent. The agent is an intermediary identity, similar in structure to a service account, but with a critical difference: the agent’s behavior is driven by a language model that interprets natural language instructions, not by deterministic code. The blast radius of “access through the agent” is harder to scope because it depends not just on what permissions the agent holds, but on what the agent can be instructed to do.
Agent identity also composes with everything else. An agent might use a service account for some operations, federate into external services for others, and hold direct IAM bindings on GCP resources. Mapping the full access surface of “user can talk to agent” requires tracing through all of these paths.
We are early in understanding what governance looks like for agent identities. But one thing is already clear: any access taxonomy that doesn’t account for non-human, non-deterministic intermediaries is very likely to age poorly.
Escalatable access
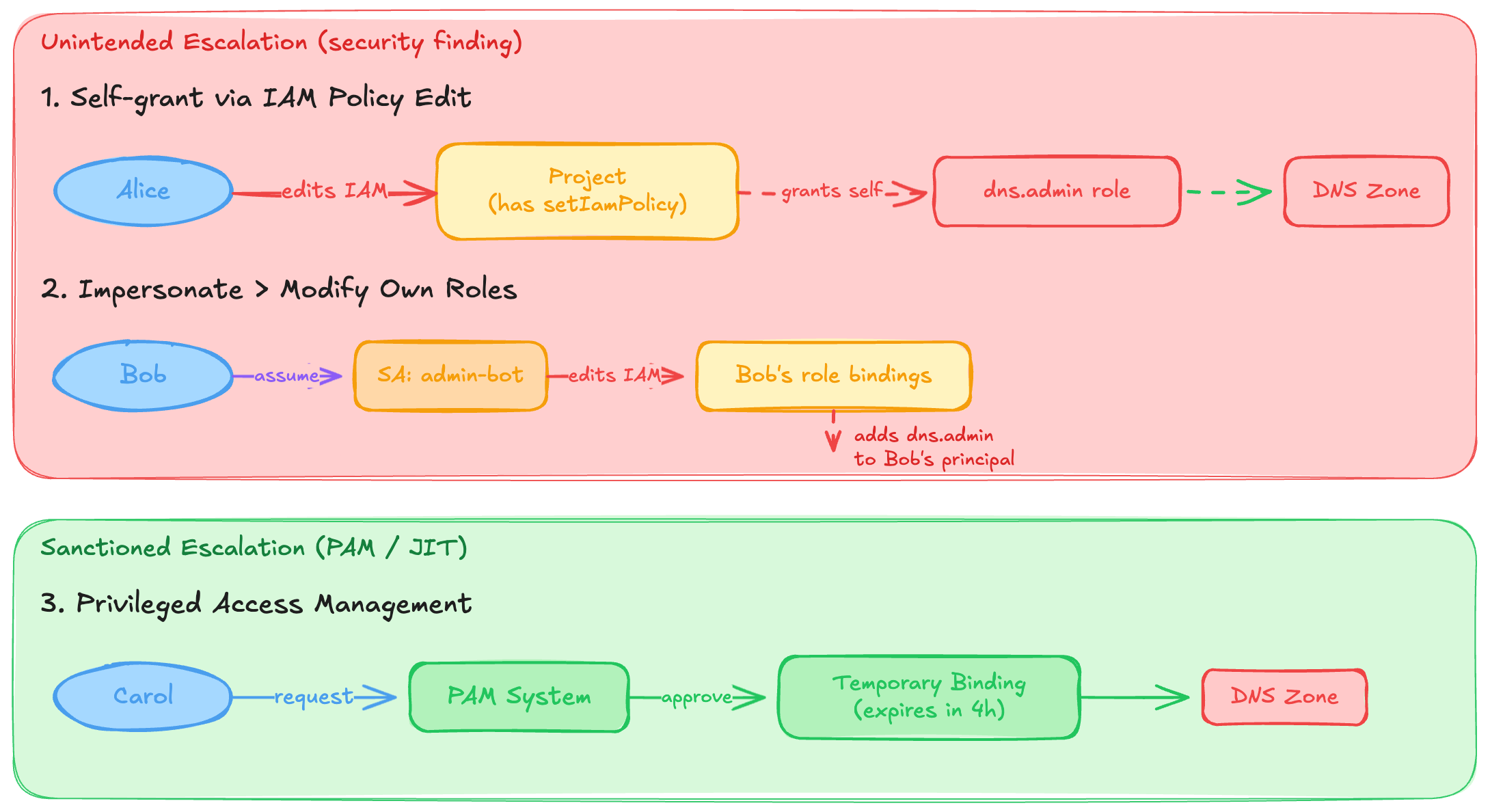
The third category is fundamentally different from the first two. Effective access and assumable access describe paths that exist. Escalatable access describes the ability to create paths that don’t exist yet.
A user with resourcemanager.projects.setIamPolicy on a project can add any role binding they want to that project. They might not have dns.changes.create right now, but they can grant it to themselves at any time. For example, a user who can impersonate a service account that has setIamPolicy on a folder can modify IAM bindings on that folder and everything below it. More subtly, a user might be able to modify their own roles: impersonate a service account that has the ability to edit the role definition or IAM policy that applies to the user’s own principal.
This is where I’d argue that access review becomes vulnerability analysis. The access path doesn’t exist yet. The user has to construct it. But if they can construct it, the access is effectively attainable from a security perspective.
Tools like PMapper exist specifically for this kind of analysis. They model IAM as a directed graph and traverse it to find escalation paths: edges that don’t represent current access, but the ability to create it. This is computationally expensive and, in the worst case, the graph of potential escalation paths grows combinatorially.
For most access review purposes, escalatable access is where you draw the line and say “this is a different exercise.” Certifying effective access is a governance activity. Reviewing assumable access is a more sophisticated governance activity. Finding and closing escalatable access paths is a security engineering problem. The vocabulary matters because it lets you be explicit about which problem you’re solving and where the boundary is.
The one exception is privileged access management. PAM and JIT access systems are, by design, sanctioned escalation: a user requests elevated permissions, approval is granted (by a human or a policy), and temporary bindings are created. This is escalatable access that’s been formalized into a workflow with controls around it. When an auditor asks about access, whether PAM grants count depends entirely on whether they’re asking about “access right now” or “access that could exist.”
In conclusion
Without shared vocabulary, every access review is a negotiation. The auditor asks “who has access,” the security team counters with “what do you mean by access,” and both parties waste time arriving at an ad hoc definition that won’t be consistent with the next review or third-party’s interpretation.
With a taxonomy, you can scope the question precisely. “Show me all principals with effective access to production DNS zones” is tractable and well-defined. “Show me all principals with assumable access, including compute-mediated impersonation” is harder but still scoped. “Show me all escalation paths to DNS write access” is a different project entirely.
This vocabulary also gives you a framework for evaluating tooling. Most cloud IAM analysis tools, including the built-in policy analyzers, primarily cover effective access. Some are specifically designed for escalatable access. Almost none handle compute-mediated assumable access or federated identity paths. Knowing which category you’re trying to cover tells you which tools are fit for purpose and where you have gaps.
More importantly, it lets you be honest about what you don’t know. Most organizations think they govern effective access reasonably well, some might even partially cover assumable access through service account reviews, but very few touch escalatable access. That is defensible, as long as it is known, understood, and stated explicitly. Issues arise when partial coverage is treated as a complete picture of access.